

The heart of data applications
_There are so many challenges and things to consider when developing data-intensive applications. How is data stored? Where is it located geographically? How is it replicated? How is consistency guaranteed? At what level? Are timestamps synchronized? What happens when the network is partitioned? Caching, sharding, split-brain, ACID, garbage collection stop-the-world, ordering of events, locks—ahhh, I think I got a 503.
When designing such systems, you typically start on the board by waving hands and drawing boxes, but the problems are usually at a deeper level and require a good understanding of the details to provide quality and integrity.
There's a lot going on under the hood when handling data pipelines. In this post, I will try to explain why it is so challenging and how you can make better decisions when designing data applications.
Although it may sound overwhelming, it usually boils down to these two concepts: availability and consistency, the yin and yang of data. It's relatively easy to achieve either one individually, but impossible to fully achieve both simultaneously. And everything in between has kept many brilliant minds busy since the first bit of data was transmitted. Let's break it down...
Availability and consistency
Availability: If a node is functioning, the request succeeds.
Consistency: Every read receives the most recent write, or an error. (For now, let's assume there's a defined order for events)
Network partitioning: The system operates, even when messages are dropped or delayed.
CAP theorem: You can't achieve all three simultaneously: consistency, availability, and network partitioning.
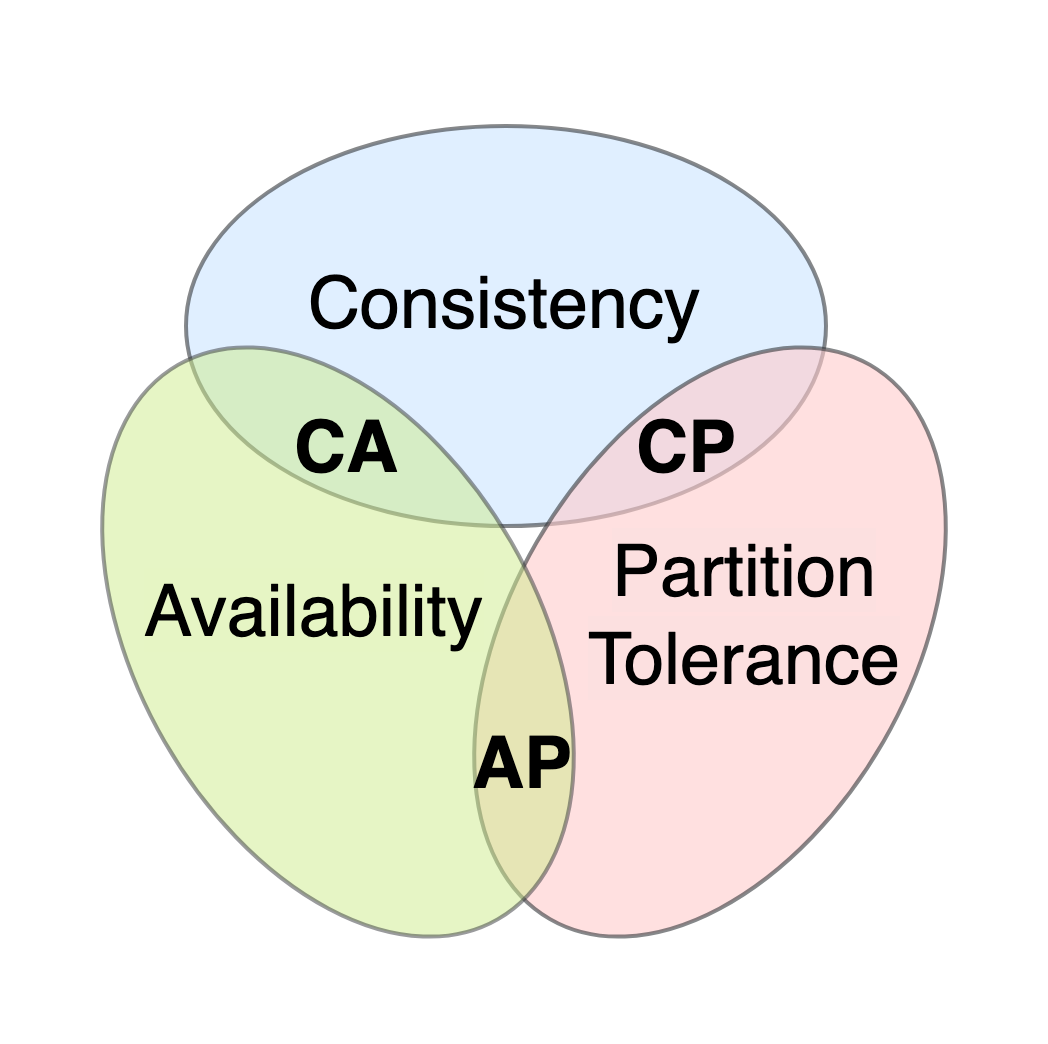
A distributed system without network partitioning is not possible (see the generals problem), and we can't allow the entire system to be corrupted because of this. So, we must choose between availability and consistency.
A simple solution for achieving consistency is to use a mutex lock and a single node. This guarantees that data is updated and read in the order of lock acquisitions. This is an example of strong consistency, where events occur in a total order.
We can improve this by replacing total order with causal order, which is achieved by locking only the specific resource. This is known as sequential consistency and is widely used in relational databases.
You can achieve availability by reading whatever is available, even if a write has started but not finished before the read request started. This gives eventual consistency, which is commonly used in NoSQL databases.
Things get even more interesting when you try to achieve availability, network partitioning tolerance, and almost consistency. This can be achieved with strong eventual consistency, which eliminates the "time travel" effect and is the heart of the book Designing Data-Intensive Applications by Martin Kleppmann (in my opinion) and many challenges in distributed systems. It can be achieved using techniques for consensus, such as quorum and fencing token.
Use-case: Data replication
Imagine you have a book that you want to share with your friends who live in different cities. Instead of physically mailing each book to everyone, you could scan it and send a digital copy to each friend. This way, everyone has their own copy, and if one copy gets lost, the others are still safe.
Data replication is like this, but with computers and data instead of books and friends. It's the process of copying data from one location (like a server) to another. This ensures that the data is accessible from multiple places, even if one location fails. It provides:
- Reliability: If the data is lost in one place, it exists in others.
- Better latency: The copy is close to the user.
- Scalability: Data is read concurrently by multiple users.
When data is replicated, there might be a short delay between when a change is made on one server and when it appears on the others. Eventually, all copies of the data will be the same, but there might be a brief period where they differ. Remember eventual consistency?
Here we favored availability over consistency, the reader replicas are accessible no matter what's their state.
Key Notes
- When designing data-intensive applications, consider the deeper levels of edge cases involved in the integrity of distributed data. It's okay not to solve every edge case, but it's important to acknowledge them and understand their potential impact.
- The core of many decisions is between availability and consistency. With availability you can achieve better performance and scale, but may reduce data integrity, and increase the complexity of properly managing it.
- There is a lot to know and learn when it comes to data management, that was just the tip of the iceberg. Curiosity is the name of the game.