

How to fail safely
_Every system, no matter how well crafted, will fail at some point. The key isn't necessarily to prevent failures – although that's certainly an amazing goal – but rather, it's about how we respond when failure inevitably comes. In this post, we'll explore strategies for managing failures in chaotic systems, from proactive design considerations to reactive recovery techniques.
Challenging Assumptions
The hardest failures I have experienced are those that broke my assumptions. Imagine a scenario where a cloud service provider experiences a widespread outage due to a hardware failure. Or a customer abused your system in a way you haven't imagined. Implement your system strictly. Known behavior should be documented and tested, unexpected behavior should be restricted by design. Validate input data, check for data integrity violations, warn about edge cases, give least privileged access, and regularly monitor your infrastructure. By documenting and challenging assumptions, you can identify potential points of failure and design plans to mitigate their impact.
One assumption that is common in every system is your knowledge about the current load on the system. Ask yourself: in X years from now, in the most optimistic scenario where the scale rises significantly, can the system handle that? By anticipating these challenges and designing systems to be resilient in such scenarios, we can ensure that they remain reliable and performant even as they grow in scale and complexity. Of course, handling large scale is not always the product priority, you can monitor that assumption to ensure you have enough space before crashing due to overload.
When writing code, my rule of thumb is that if you write code based on something that you know, but someone else is not expected to know, you should add a code comment about that assumption and why you made this decision. Or- write the code in a way that doesn't assume that.
Failure Modes
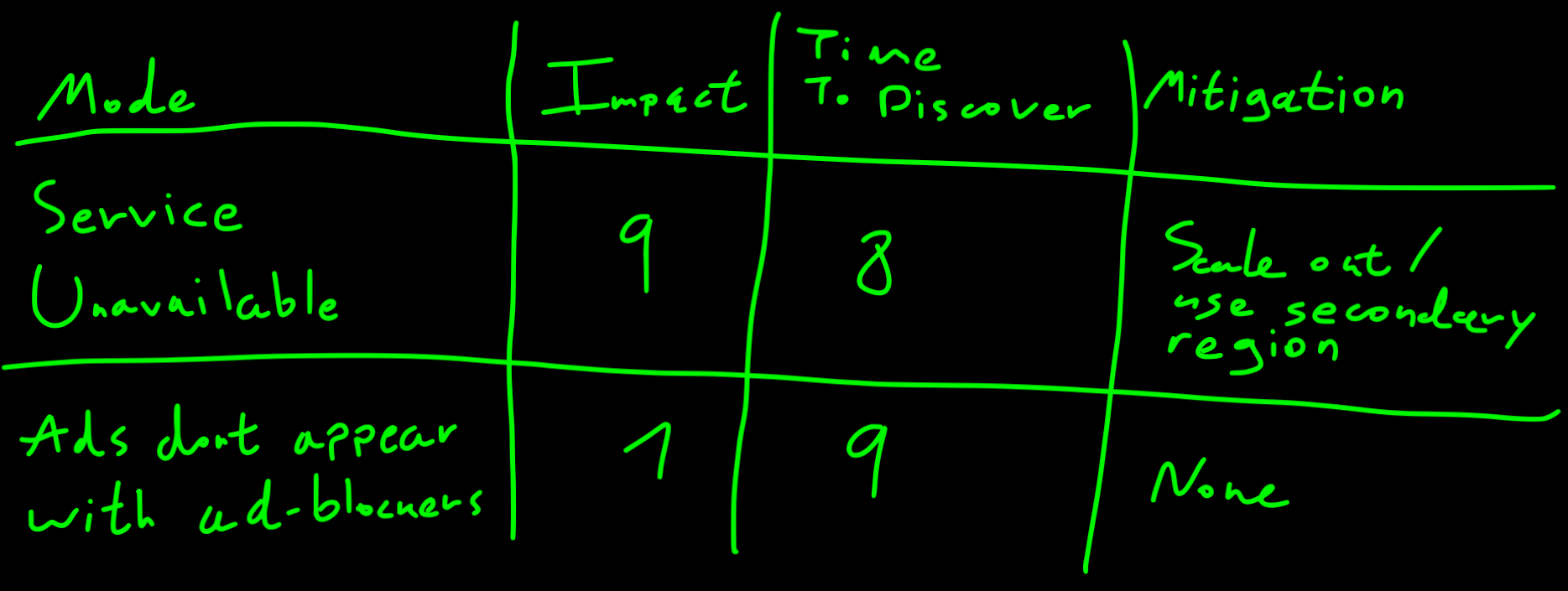
Before we jump into strategies for managing failure, it's crucial to understand the different failure modes that can impact a system. Consider the challenge of maintaining consistency control in a distributed database serving millions of users concurrently. As the system scales, edge cases and corner scenarios become more common, increasing the likelihood of failures due to race conditions, network partitions, and data inconsistencies. If the timeline of the project doesn't allow facing the issues right now, at least open a tech-debt and document the possible failures. By the way, that's not only an engineering concern.
Practically speaking, every failure mode should be categorized by scoring the following attributes on a scale from 1-10:
Impact: This attribute refers to the extent of the damage or disruption caused by a failure. It includes financial losses, customer dissatisfaction, and damage to reputation. Understanding the potential impact of failures helps prioritize mitigation efforts and allocate resources accordingly.
Time to Discover: The time it takes to detect a failure is critical for minimizing its impact. In some cases, failures may be immediately apparent, while in others, they may stay unnoticed until they wakening more significant issues. Shortening the time to discover failures requires robust monitoring and alerting mechanisms that can quickly identify anomalies and trigger appropriate responses.
Mitigation Strategies: Once a failure is detected, the next step is to mitigate its impact and restore normal operation. Mitigation strategies may include implementing redundancy, failover mechanisms, or automated recovery processes. The effectiveness of these strategies depends on factors such as system architecture, resource availability, and the nature of the failure itself.
By considering these attributes when analyzing failure modes, you can develop proactive strategies for prioritizing tech debts.
Change Management
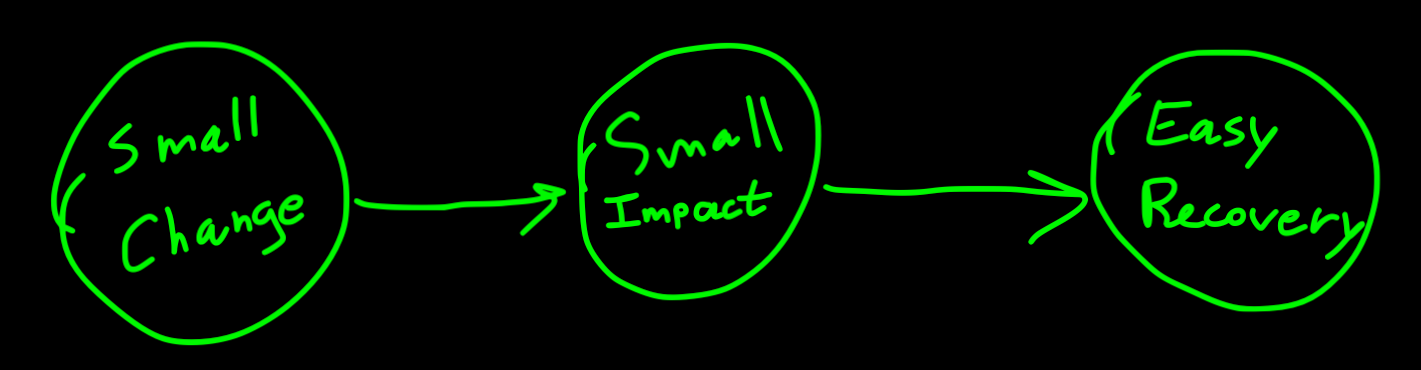
Change management is important for finding out why things go wrong. Teams can keep track of changes better by using a well-defined tasks management system and linking each change to the code it affects. For example, if something suddenly starts working badly after a deployment, teams can quickly find out why by looking at what changed in the code and revert it if needed. Also, when making infrastructure changes, it's helpful to use IaaC tools like Terraform so you would be able to track the changes via code. Making smaller changes also helps because it is simpler to do a good code review, it is easier to see what went wrong, it reduces failures impact, and it is faster to revert. By being organized with changes, you can fix problems faster, making the system work more reliably.
One way of tracking and linking changes is by practicing GitOps, which makes the code the source-of-truth of changes. For example, you can run the CI pipeline on every push, deploy to production on tag creation, and undo changes using git revert.
One type of change that requires extra attention is...
Breaking Changes
A breaking change is a change of a component that would cause another component to break unless modified to support that change. This could involve updating code, configurations, or contracts. They can be unintentional, such as when a bug fix alters the behavior of a function, or intentional, such as when a new feature requires changes that are incompatible with previous versions. In either case, you should minimize breaking changes whenever possible to ensure smooth transitions and maintain compatibility for users.
In such cases, you should also consider the order of deployments, and dependencies coming from various environments. For example, if you deploy two components together: A v2, and B v2 while A v2 breaks B v1, and B v2 is compatible with A v2, things would get broken if A v2 is deployed before B v2 finished the deployment. What you need is to break down the deployment so B would support both A v1 and v2, then deploy A v2, and then deploy B v2 that cleanup support for A v1.
Besides the obvious integration and E2E tests, you can have contract tests, see PactFlow for example.
Failures Discovery
From design to deployment, monitoring, and recovery, handling failure should be a central consideration at every stage of the development lifecycle. For example:
- Add a section in your design about failure handling.
- Have a good basis for error handling throughout the code.
- Write automated tests that validate the resilience of the system.
- Have proper local and live development environments for testing changes before deploying to production.
- Conduct load tests to see how close your system is to its limit.
- Perform QA tests and regression tests.
- Monitor production.
- Prioritize tech debts based on the failure mode score.
Fail-fast VS fault-tolerant
Prefer fixing the root cause of the failure, rather than patching and tolerating it. Silent errors may cause a ripple effect that hits something important, far away from the root cause. Consider a case where you persist in a faulty state in the database to avoid a failure, and then a month later a customer does some operation on the corrupted resource, which causes a complete mess.
In another case, retrying failing messages may cause more load on the system. If the failure is due to overload, the retrying would cause more overload, which in turn causes more errors. If you do retries on failing messages, do that only on retriable errors and consider the timing between attempts.
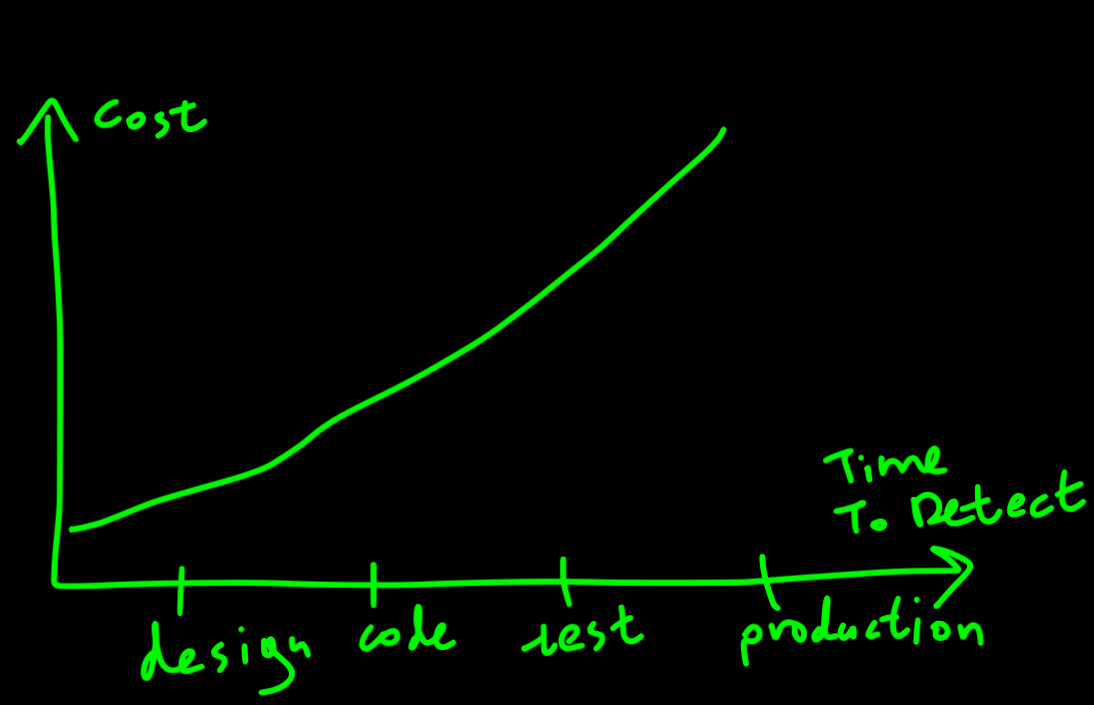
It would be easier to find the root cause if your code is strict, and explicitly fails. You can include information that would help to tailor error handling specific to the context of the error. Failing fast would also help during the early stages of development detecting that something is not working right, rather than silently ignoring it.
Having said that, if done wisely, fault tolerance is important for business continuity. Tolerate errors on upper layers, monitor them, and calmly notify that an error has occurred.
The rise of microservices architectures has introduced new challenges and opportunities for resilience. By embracing principles such as loose coupling, fault isolation, and graceful degradation, you can build systems that are resilient to failure at scale. For example, implementing circuit breakers and fallback mechanisms can prevent cascading failures and ensure that individual service failures have minimal impact on the overall system.
This leads me to the next topic...
Defining Operational Excellence
What does it truly mean for a service to be operational? Consider a cloud-based file storage service with a defined SLO (Service Level Objective) of 99.999% (five nines) uptime. This means that the service should be available for at least 99.999% of the time in a given period, with downtime limited to 05:15 minutes a year. By establishing clear SLOs and monitoring performance against these objectives, you can identify areas for improvement and take proactive measures to enhance system reliability. Start by writing down your features, and for each feature define what it means for it to be available. Set a metric to measure the availability of that feature, and implement recurring tests in production (AKA smoke tests) that would set a data point in the measurement. Now, depends on your SLO, decide how frequently you want to measure it and end with a monitor that triggers when you are close to SLO impact.
Failures Observability
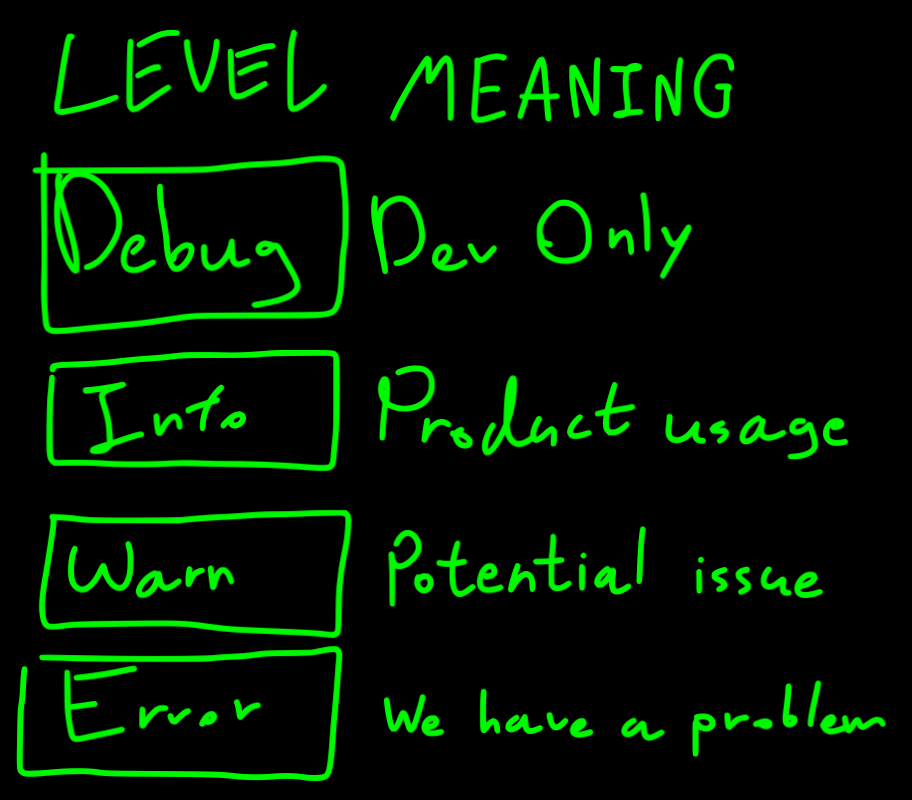
Logs, stack traces, error codes – these are the breadcrumbs that lead us to the source of failure when things go wrong. However, not all logging and monitoring practices are created equal. Consider a scenario where a distributed microservices architecture generates an overwhelming volume of log data, making it challenging to distinguish between critical errors and irrelevant warnings. You can filter out noise and focus on actionable insights for rapid diagnosis and resolution of issues.
From my experience, there is a correlation between the quality of the code and the amount of noisy logs. Maybe it is because there isn't a good error-handling framework, or because you don't trust basic lines of code. Either way, the solution usually is not to put more logs, as it just puts more fog on the real problem. Implement good error handling throughout the code and test that it works when failure happens. Every failure should be logged once with maximum context, where the context may include: stack trace, internal error codes, identifiers of relevant identifiers like customer ID, etc. Try to write a short message with a minimum amount of context. Put the context details in tags.
For example, prefer this:
{
"msg": "User creation failed",
"level": "warn",
"http": {
"statusCode": 409,
"url": "/user",
"method": "POST"
},
"error": {
"code": "UNIQUE_USERNAME_CONFLICT",
"stack": "longstacktrace.ts at line 45"
},
"conflictContext": {
"username": "xyz",
"customerId": "abc"
}
}
Over this:
{
"msg": "Error UNIQUE_USERNAME_CONFLICT: Customer 'abc' failed to create user, because username 'xyz' already exists. Failed with status code 409 on POST /user. Error UNIQUE_USERNAME_CONFLICT. Stack trace:\nlongstacktrace.ts at line 45",
"level": "warn"
}
Besides error and warning logs, send metrics on successful operations, because silence is more scary than failing, and monitor when success metrics are too low. Also measure the performance of focal points in the system, especially if you have latency thresholds in your requirements and alert when something unexpected occurs, along with SLO budget consumption.
Dashboards and visualization tools can provide insights into system health and performance. A real-time dashboard that aggregates metrics from across a distributed system, can present a holistic view of system performance in an easily digestible format. By having charts, graphs, and heatmaps, you can quickly identify trends, anomalies, and performance bottlenecks, enabling rapid decision-making and proactive intervention. From my experience, this part is a game changer while fixing production issues as it helps you quickly understand where the problem is and whether the system is operational.
Fail partially
When releasing a new feature that hasn't been tested in production yet, you better take things slow and steady. Instead of giving everyone the new update all at once, you can do it bit by bit to test things out. You can do that by slicing the release to multiple deployments, or by exposing it to some portion of your customers to get feedback. This can be controlled with smart back-office dashboards and flags that control the code's flow or API gateway rules.
Besides controlling the order of deployments and the customer flags, you can use techniques to gradually deploy changes to production, like blue-green and canary deployments. This allows you to test things out in a production environment without affecting all the servers at once.
It will also help you with the next section...
Rapid Recovery
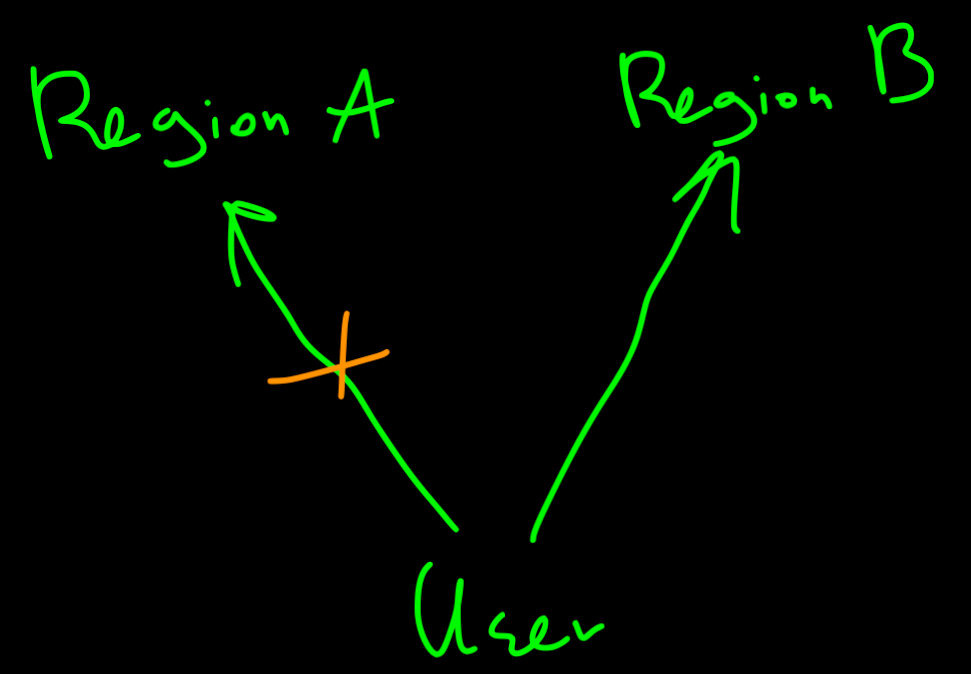
You have a production issue, congrats! A huge amount of users suddenly overwhelmed the system and an important service is having a hard time. Fast recovery methods like auto-scaling, multi-region and fast hot-fix deployment processes would help you resolve the issue fast. Moreover, keep backups and disaster recovery plans to ensure data would not be lost in catastrophic events.
The two main metrics for resolving production issues are:
- RPO (Recovery Point Objectives), which measures the amount of persisted data lost.
- RTO (Recovery Time Objectives), which measures the amount of time the service was unavailable.
Write a plan for when an outage happens. Conduct fire drills to ensure that the plans work, the monitors alert and whether you are missing something that might help you in a real scenario.
Continuous Learning and Improvement
Failures are goldmines for knowledge. Use the metrics, logs and archived data to investigate the root cause of the failure, why it happened and what actions should be taken so it won't happen again. Continuously iterating on our systems based on these learnings is essential for building resilience.
Be transparent with your team and dependant teams about what happened, and focus on what you learned and what helped, or could help you make the system better. This would not only build trust but also an opportunity for everyone to see the bigger picture and learn from mistakes.
Conclusion
Managing failures in chaotic systems requires a combination of proactive design, reactive response strategies, and a continuous commitment to learning and improvement. By embracing failure as an inevitable aspect of any system, and by considering resilience throughout the development lifecycle, you can become better at landing on your feet. Like a cat.